|
|
Emeagwali's answers to frequently asked questions.
 What are distributed and parallel computing? What are distributed and parallel computing?
 There are technologies used to harness the power of thousands of
“electronic brains” called microprocessors.
Your personal computer is powered by one microprocessor,
while a supercomputer is powered by up to 65,536 microprocessors.
There are technologies used to harness the power of thousands of
“electronic brains” called microprocessors.
Your personal computer is powered by one microprocessor,
while a supercomputer is powered by up to 65,536 microprocessors.
I was the first to program a 65,536-processor parallel computer to
outperform a conventional supercomputer. The key to my discovery was
visualizing the names, locations and 12 nearest nodes of each processor.
My 65,536 processors were networked as a 12-dimensional hypercube with
16 processors at each of its 4096 (two to the power of 12) nodes.

Emeagwali
Artist's illustration of my chicken vs. oxen metaphor in which I succeeded in demonstrating
that 65,000 chickens
(inexpensive computers) are more powerful than a single $100 million supercomputer.
(Courtesy of "One of the World's Fastest Humans," Michigan Today, February 1991)
Do you believe that distributed computing is more powerful than parallel computing?
I disagree with the claim that clusters are cost-effective for seismic modeling. Clusters are B-grade supercomputers with advertised high theoretical computational speeds. You cannot perform petroleum seismic simulation with theoretical horsepower.
If you look under the hood, so to speak, you will see that the computing nodes of a massively parallel supercomputer are tightly-coupled, while those of a cluster are loosely-coupled.
The laws of physics used in discovering and recovering petroleum are codified using an advanced form of calculus called partial differential equations. Prior to solving these equations on a supercomputer, the computational mathematician must reduce them to a discretized format that is defined over millions of tightly-coupled points. The supercomputer programmer will obtain low practical speed when a tightly-coupled problem is distributed amongst loosely-coupled clusters of computers. Therefore, the most efficient computing paradigm for seismic and reservoir simulation will remain a massively parallel computer.
Furthermore, I demonstrated in my 1988 discovery that it is practical and cost-effective to tightly couple 65,536 processors within a refrigerator-sized computing machine. For the sake of comparison, it would require a big building to house a cluster of 65,536 servers that are stacked on metal racks.
What is a hypercube?
A hypercube is a cube in a higher-dimensional world.
I visualized my processors at the vertices of a hypercube.
Below is an illustration of the information pathways that I used to
construct high-dimensional hypercube configurations. Each hypercube
was constructed by moving the next lower hypercube along an additional
direction. For example, my 7-dimensional hypercube was constructed
by moving my 6-dimensional hypercube along the seventh dimension.
A three-dimensional cube contains eight vertices with three edges
emanating from each vertex. Below is a five-dimensional hypercube
that contains 32 vertices with five edges emanating from each vertex.
A sixteen-dimensional hypercube contains 65,536 vertices with sixteen
edges emanating from each vertex. I visualized my 65,536-processors as
a 12-dimensional hypercube with 12 bi-directional communication channels
emanating from each computing node and 16 processors on each node.
The above enabled me to create the new knowledge for controlling and
instructing the flow information and data along the twelve bi-directional
communication channels of a
12-dimensional hypercube computer.
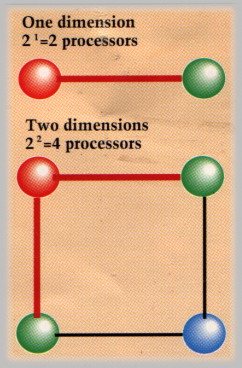
Emeagwali
A hypercube with one and two nodes.
How did you program thousands of processors to achieve your world record?
First, I began with a map of the names, locations and links to all 65,536 processors.
The links of my hypercube computer correspond to the edges of the associated hypercube graph.
A better understanding of my hypercube topology is gained by studying how a hypercube graph is
constructed from the next lower-dimensional hypercube graph.
An N-dimensional hypercube graph can be constructed from two (N-1)-dimensional
hypercube graphs by connecting the corresponding vertices of the two graphs.
The new binary representation of the vertices is changed by giving vertices of one graph the highest-order
address bit 0 and giving the vertices of the other the highest-order address bit 1. The example of
how to build and number a four-dimensional hypercube computer from two three-dimensional hypercube
computers is illustrated in the figure below.

Emeagwali
Two, 3-, 4-, 5-, 6-, and 7-dimensional hypercube configurations, respectively.
Figure also illustrates how higher dimensional hypercubes can be constructed from lower dimensional ones.
(Illustration by Mathworld)
The five colors in my five-dimensional hypercube graph below show the five independent paths of
a five-dimensional hypercube, which can be used to deliver a message between any two
processing nodes that are the farthest possible distance apart. Similarly, N colors can be used to
show the N independent paths of an N-dimensional hypercube that can be used to
deliver a message between any two processing nodes that are the farthest possible distance apart.
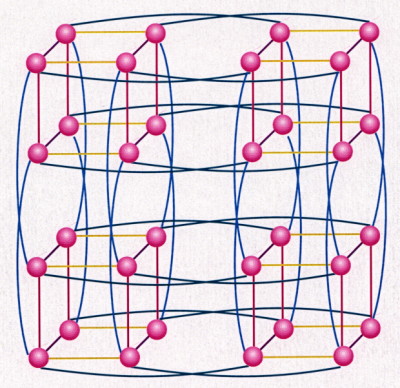
Emeagwali
The graph of my five-dimensional hypercube with 32 vertices. In my mental image of my
32-node, five-dimensional hypercube computer (shown above), the pink
dots represent my computing nodes
and the lines represent my communication channels.
Every node in my hypercube computer is identified by a unique binary number which consists
of 0's and 1's. The length of these binary numbers is equal to the dimension of the hypercube computer.
Their values, in the decimal numbering system, range from zero to the number of processing nodes
minus one, inclusive. These binary representation numbers are uniquely arranged in a sequence
generated by using the binary-reflected Gray code. The binary-reflected Gray coded numbering
system is illustrated in Figure 1 for the cases of zero-, one-, two-, and three-dimensional hypercube
computers.
The reason that I preferred the binary-reflected Gray code over the other binary Gray codes is
that it allowed me to easily compute the number of nodes that must be traversed in sending a
message between any two nodes of my hypercube computer. In other words, it allowed me
to compute how far apart any two processing nodes, within my binary hypercube computer, are from
each other. As can be deduced from the illustration, this distance is is equal to the number of bit
representations by which their binary identification numbers differ. Hence, two processing nodes are
nearest neighbors if their binary representation differs by exactly one bit position. For example, my
parallel computer was a twelve-dimensional hypercube computer, and, consequently, each node within it
could be uniquely identified by a 12-digit binary number. Those represented by the 12-digit binary
numbers 000 001 000 000 and 010 001 000 000 are nearest neighbors, while those represented
by 000 111 000 000 and 000 000 111 000 are a distance of 6 units apart. Using the same reasoning,
I can show that the average distance between any two processing nodes is N/2, that the greatest distance
between any two processing nodes of a hypercube graph is not greater than the dimension of my
hypercube computer, and that each processing node of my N-dimensional hypercube computer
has N links that directly connect it to N other processing nodes which are also its
nearest-neighbor nodes.
I prefer the HyperBall over the hypercube. The reason is that a hypercube computer has several
disadvantages. First, the hypercube computer uses a large
number of expensive communication channels. This is because when the number of processing
nodes are doubled, the number of communication channels are more than doubled. For a
system that has the capability to perform bi-directional internode communication, if processing nodes
are used, then communication channels must be used. For example, the ten-dimensional model of a
hypercube computer series has processing nodes and 10,240 bidirectional communication channels.
On the other hand, the eleven-dimensional model of the same series has 2048 processing nodes
and 22,528 communication channels. As we can see, merely doubling the number of processing
nodes more than doubles the required number of communication channels. This disproportionate
growth in the number of communication channels gets even worse as the number of processing nodes
used increases. In comparison, each node of a k-dimensional mesh computer has 2k
communication
channels. Therefore, the total number of communication channels of a mesh computer grows at the same
rate as the nodes.

A three-dimensional hypercube graph.
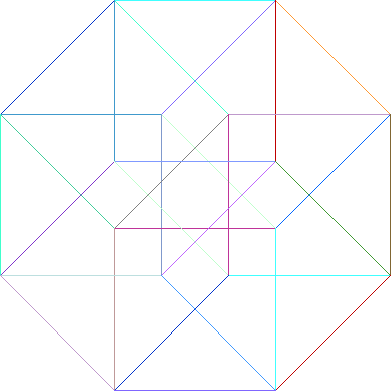
A four-dimensional hypercube graph.

A five-dimensional hypercube graph.
A six-dimensional hypercube graph.
A seven-dimensional hypercube graph.

An eight-dimensional hypercube graph.
A nine-dimensional hypercube graph.
A ten-dimensional hypercube graph.
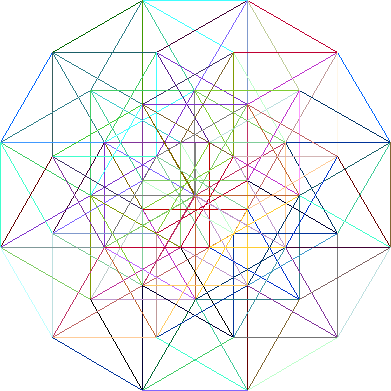
An 11-dimensional hypercube graph.

A 12-dimensional hypercube graph. The information pathways of the
4096 nodes of my twelve-dimensional hypercube. Each node
(symbolically represented by a point) has twelve communication
channels (represented by a line) emanating from it.
A 13-dimensional hypercube graph.
A 14-dimensional hypercube graph.
A 15-dimensional hypercube graph.
Have you established a new world computational speed record?
Although, I programmed 65,536 processors to perform the world’s
fastest computation (i.e. 3.1 billion calculations per second
in 1988). However, I never set out to establish a world computing record. It
made the headlines because it had, at that time, been widely
believed that it would be impossible to program thousands of
processors to outperform conventional supercomputers.
Although the supercomputer was my claim to fame,
my research was never on supercomputers, per se. It
was on the kernel of knowledge that powers both the supercomputer
and the Internet. My focus is on the conceptual foundation of
the next-generation Internet, namely computation and
communication.
The essence of my research was to demonstrate that thousands of inexpensive processors could outperform any supercomputer. In other words, I wanted to create the knowledge that supercomputers should utilize thousands of processors.
In 1988, I announced that I had successfully divided a petroleum reservoir into 65,536 smaller problems and then mapped, communicated and distributed them to 65,536 processors of the Connection Machine, all networked together as a 12-dimensional hypercube with 16 processors at each of its 4,096 nodes.
The hypercube was a cube in 12-dimensions with 4,096 (two to power 12) vertices. I used 4,096 nodes (i.e. two raised to power 12) because it enabled me to map my problem onto a 12-dimensional mathematical hyperspace. I projected a three-dimensional problem onto a 12-dimensional hypercube space, and projected it back into three-dimensional space.
In the 1980s, the debate among supercomputer manufacturers was: “Is it practical to use thousands of processors?” The manufacturers’ consensus was “no.” I answered “yes” by using 65,536 processors to solve one of the 20 most difficult problems in the computing field. My original calculations were conducted with the partial differential equations used in petroleum reservoir simulators. However, it was understood that my mathematical, programming and mapping techniques could be extrapolated to equations used for climate, cosmological, and other computation-intensive simulations. The latter achievement eventually became my “claim to fame.”
What did you contribute to the reinvention of supercomputers?
I added new knowledge that is incorporated inside all
supercomputers.
I took parallel computing to a higher level than the supercomputer, an
achievement that inspired the reinvention of the supercomputer. In
The New York Times (11/29/89), the
president of the leading supercomputer manufacturer warned,
"We can't find any real progress in harnessing the power of thousands of
processors." A few weeks later, my discovery of the formula that
allows parallel computers to perform their fastest computations
started making the headlines.
My formula enabled me to subdivide the problem into smaller parts
and re-distribute the parts to 65,536 processors. That discovery
inspired the reinvention of vector supercomputers as parallel
supercomputers. Vector supercomputers use an ultra-expensive
processor designed to perform the fastest calculations on long
strings of numbers called “vectors.”
I created the knowledge that the power of thousands of processors can
be harnessed; this knowledge, in turn, inspired the reinvention of
supercomputers powered by only one processor as supercomputers powered
by thousands of processors. Since my discovery - in part - opened and
prepared the technology for commercialization, I am considered a pioneer
in parallel computing.

Emeagwali
My wife and I at the Gordon Bell Prize award ceremony, Cathedral Hill Hotel, San Franscisco, CA.
February 28, 1990.
Updates by Webmistress
The Reviews
Emeagwali's discoveries described above inspired Bill Clinton
to extoll him as "one of the
great minds of the Information Age." CNN and the Institute of Electrical
and Electronics Engineers also commended him
for contributing to the reinvention of the supercomputer.
Emeagwali's
Contribution
In the 1980s, the debate among supercomputer manufacturers was: Is it
practical to use thousands of processors? The consensus was NO. IBM's top computer designer, Gene
Amdahl, postulated, in a classic paper written in 1967, that it will be
impractical to use many processors to solve real-world problems.
On November 29, 1989,
the president of Cray, the leading supercomputer manufacturer,
told The New York Times:
"We can't find any real progress in harnessing the power of
thousands of processors"
Emeagwali disagreed and distributed
copies of his 1057-page report
that provided a detailed step-by-step method for harnessing the
power of 65,536 processors. This work led to the reinvention of
supercomputers, from using one processors to using hundreds or thousands of
processors.
The CNN described Emeagwali's
reinvention of the supercomputer as follows:
"It was his [Emeagwali] formula that used 65,000 separate
computer processors to perform 3.1 billion calculations per
second in 1989. That feat led to computer scientists
comprehending the capabilities of supercomputers and the
practical applications of creating a system that allowed
multiple computers to communicate. He is recognized as one
of the fathers of the Internet."
Emeagwali's groundbreaking studies that changed the way
IBM thinks about supercomputers almost didn't get published.
At first rejected for bucking the conventional
theory of the
day, it was
finally published after it won the
1989 Gordon Bell Prize, computation's
Nobel prize.
The Importance
This work was a fundamental shift in supercomputer design --- incorporating thousands of weak processors instead of one
powerful one. IBM summarily rejected his proposal to employ or fund his
initial research. Today, computer giants now use
the technology to manufacture supercomputers.
Since the
supercomputer of today is the computer of tomorrow, technological
inventions
are the lifeblood of the information technology industry. For
hardware manufacturers, such as IBM, they are vital technologies
that enable them to compete, diversify and expand. In fact, since
one-third of the US economic growth is now attributed to information
technology, new computer inventions are also the lifeblood of the
American economy.
Put simply, the United States needs more powerful
computers for growth, profitability and global competitiveness.
Lesson Learned
Any new idea that is a radical departure from the accepted
status quo
goes through three stages: Rejection, Ridicule, and Acceptance.
For an idea to gain acceptance, the originator must continue to harp on it
even when the listeners find it annoying. The struggle to get an innovative
idea accepted is greater than the struggle to conceive it.
As writer George Bernard Shaw
said:
"The reasonable man adapts himself to the world; the unreasonable man
persists in trying to adapt the world to himself. Therefore, all progress
depends on the unreasonable man."
Excerpted from:
- History of the Internet, by Christos J. P. Moschovitis, et al, 1999
- Upstream, Oslo, Norway (oil & gas industry publication), January 27, 1997
- Software, Institute of Electrical and Electronics Engineers, May 1990
- SIAM News, Society of Industrial and Applied Mathematics, lead story, June 1990
- CNN, http://fyi.cnn.com/fyi/interactive/specials/bhm/story/black.innovators.html
- The New York Times, November 29, 1989.
- The White House, http://clinton6.nara.gov/2000/08/2000-08-26-remarks-by-the-president-in-address-to-joint-assembly.html
SHORT BIO
Emeagwali was born in Nigeria (Africa) in 1954. Due to
civil war in his country, he was forced to drop out
of school at the age of 12 and was conscripted into
the Biafran army at the age of 14. After the war ended,
he completed his high school equivalency by self-study
and came to the United States on a scholarship in March
1974. Emeagwali won the 1989 Gordon Bell Prize,
which has been called "supercomputing's Nobel Prize,"
for inventing a formula that allows computers to perform
fast computations - a discovery that inspired the
reinvention of supercomputers. He was extolled by the
then U.S. President Bill Clinton as "one of the great
minds of the Information Age” and described by CNN
as "a Father of the Internet." Emeagwali is the most
searched-for modern scientist on the Internet (emeagwali.com).

Click on emeagwali.com for more information.

|
